Task 2c: How to Generate Population Counts in Stata
In this example, you will use Stata to combine age subgroups and generate
population estimates for high blood pressure (HBP) by sex and race/ethnicity for
persons 20 years and older. The method outlined in this module uses a Stata
data file with CPS population totals. The process for combining subgroups and
calculating population estimates is then automated using the code outlined
below.
Alternatively, you can use the CPS population totals located on the
respective survey cycle NHANES web page (referred to in Key Concepts), plus the
results from a syv:mean command and manually calculate population
estimates within a spreadsheet. If you choose this option, you will need to
define the age, race/ethnicity and gender subgroups of interest and calculate
population totals within the spreadsheet on your own.
Step 1: Download and install parmest command
The program outlined in the following steps uses a command called parmest
that saves a model fit as a dataset. If you do not have this command installed
and run the program, it will report an error that the parmest command is
not recognized. You will use Stata Help to locate, download
and install this command. In Stata, open the Help menu in the top toolbar. Then
select Search. In the dialog box, select the radio button next to "Search All",
and enter "parmest" in the search field. In the results, click the result
"dm65." If you do not have this command installed, you will see a brief
description and "(Click here to install)" in blue on the right side of the
window. Click it to install. (If you already have this command installed, you
will get the complete Help file and list of options to use with the command.)
Do not install dm65_1. The program will generate errors
if dm65_1 is installed instead of dm65. This is because
the parmest command that is installed with dm65_1 does
not restore the existing dataset (analysis_data) after the command
parmest, (save filename) is used to save the most
recently requested parameter estimates. If you accidentally
installed or already installed dm65_1, go back to the
search results and click dm65 and select the option to replace
dm65_1 with dm65.
Step 2: Use svyset to define survey design variables
Remember that you need to define the SVYSET before using the SVY series of commands.
The general format of this command is below:
svyset [w=weightvar], psu(psuvar) strata(stratavar) vce(variance
method)
To define the survey design variables for your high blood pressure analysis, use the weight variable
for four-years of MEC data (wtmec4yr), the PSU variable (sdmvpsu),
and strata variable (sdmvstra) .The vce option specifies the
method for calculating the variance and the default is "linearized" which is
Taylor linearization. Here is the svyset command for
four years of MEC data:
svyset [w=
wtmec4yr], psu(sdmvpsu) strata(sdmvstra) vce(linearized)
Step 3: Create new variables
You will need to create variables for age, race, standard weight, and high
blood pressure. First, create a variable for the race/ethnicity groups in your
analyses. Then, code the outcome variable as a dichotomous variable, where the
absence of of the outcome is coded as 0 and the presence of the outcome is coded
as 100. Using 100
will express the proportion as a percentage (e.g., 0.23 would be represented as
23). The dichotomous variable, hbp, is already coded as 2 for the absence
of outcome and 1 for the presence of outcome, so it will need to be recoded as a
new variable, hpbx. Here is the code for creating the variables:
Code to generate variables
| Variable |
Code to generate variables |
| Race |
gen race =1 if
ridreth1 == 3
replace race =2 if ridreth1 == 4
replace race =3 if ridreth1 == 1
replace race =4 if ridreth1 == 2 | ridreth1 ==5 |
| High Blood Pressure |
gen hbpx=100 if
hbp==1
replace hbpx=0 if hbp==2 |
Step 4: Generate proportions for the outcome of interest and save estimates
The STATA command, svy: mean, and additional STATA code will be used
to generate population estimates. Similar to the svy: mean command used
in Task 1, you will output the results to a STATA data file using the parmest command, as shown below.
Population estimates will not be age-standardized so that they reflect the true
population sampled.
quietly svy, subpop(condition): mean
var
estate size
parmest, saving("path\to\file", [option])
Use the prefix quietly before the svy command to suppress terminal output. Use the svy:mean command with the high blood pressure variable (hbpx) to estimate the prevalence of HBP. Use the subpop() option to select a subpopulation for analysis, rather than select the study population in the Stata program while preparing the data file. Use the estate size post estimation command to display subpopulation sizes. Use the parmest command with the saving option to create a new Stata dataset of the most recently requested parameter estimates.
quietly svy, subpop(if ridageyr >=20
& ridageyr < .): mean hbpx
estate size
parmest, saving("c:\NHANES\data\popmean1", replace)
The output data will be formatted so that it can merged in a later step.
use "c:\NHANES\data\popmean1", clear
gen riagendr=0
gen race=0
drop parm
save "c:\NHANES\data\popmean1", replace
Step 5: Combine CPS population tables
In this step, you will combine appropriate CPS population
totals across survey cycles AND across years of age to reflect the subpopulation
of interest (i.e., those 20 and older by sex and race).
In this module, CPS population totals are supplied as a
Stata dataset with values for: age (CTUTAGE) ranging from 0 to 85+ years
; gender (CTUTGNDR); race/ethnicity (CTUTRACE), where 1=
non-Hispanic white, 2=non-Hispanic black, 3=Mexican American and 4=other;
race/ethnicity (CTUTRETH), where 1=Mexican American, 2=non-Hispanic
other, 3=non-Hispanic white, 4=non-Hispanic black, 5=other Hispanic; ethnicity
(CTUTHISP) where 1=Hispanic and 2=non-Hispanic; survey cycle (CTUTSRVY);
and the population total (CTUTPOPT). Appropriate age, race/ethnicity,
and gender groups were created in a previous step.
The collapse command in Stata will be used to
calculate CPS population totals for the sub-domains of interest (i.e., sex and
race/ethnicity) for the subpopulation of interest (age 20 and older). In this
case, no sample design factors or weights need to be used. Use the use command to load the Stata-supplied dataset (cpstot9902)
to read the CPS population totals. The variable is CTUTPOPT (the population
totals). Subgroup totals are output to another Stata dataset (poptot9902)
for use in the next step. Nothing is printed. Use the collapse command to
convert the current dataset into a dataset of population total sums for
ages greater than or equal to 20 years. Use the
save command to save the dataset.
use "C:\NHANES\data\cpstot9902.dta ", clear
collapse (sum) ctutpopt if ctutage >=20 & ctutage <.,
save "c:\NHANES\data\tot9902a", replace
Step 6: Multiply prevalence estimates with CPS population totals
In this step, you will multiply prevalence estimates
with corresponding CPS population totals to estimate the total
number of non-institutionalized U.S. citizens affected with HBP.
Note that the datasets produced in the previous steps (popmeans,
poptot9902) were sorted on the
sub-domain variables (riagendr, race) to be merged. After
merging, the prevalence estimates output from the datasets are rounded.
use "c:\NHANES\data\popmeans", clear
merge riagendr race using "c:\NHANES\data\poptot9902.dta"
gen est=round(estimate,.01)
gen se=round(stderr,.01)
gen ll=round(min95,.01)
gen ul=round(max95,.01)
Then, percent prevalence estimates
(est), as well as
lower and upper 95% confidence limits (ul, ll), will be multiplied to the
corresponding population total for that subgroup (ctutpopt).
gen popmean=(est/100)*ctutpopt
gen popl=(ll/100)*ctutpopt
gen popu=(ul/100)*ctutpopt
Results will be rounded,
saved, and printed.
gen popmeanr=round(popmean,1000)
gen poplr=round(popl,1000)
gen popur=round(popu,1000)
gen poptot_r =round(ctutpopt,1000)
save "c:\NHANES\data\popmeans", replace
list riagendr race est se ll ul poptot_r popmeanr poplr popur, clean
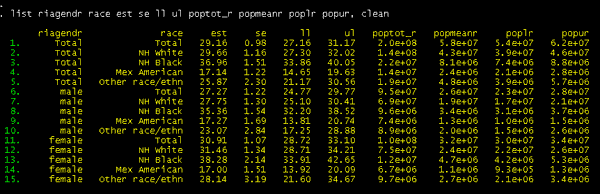
Highlights from the output
include:
-
Nearly 58 million
non-institutionalized U.S. adults have high blood pressure, with
approximately 26 million adult men and 32 million adult women
affected.
- The number of non-institutionalized U.S. adults with hypertension, by
race/ethnicity, is as follows: approximately 42.7 million
non-Hispanic Whites, 8.1 million non-Hispanic Blacks, and 2.4
million Mexican-Americans.
 Close Window
Close Window