Typically, a sufficiently large probability sample, will have point estimates
that are approximately normally distributed. The end points of the confidence
interval, then, are a function of the estimate (![]() ), its standard error
(
), its standard error
(![]() ), and a
percentile of the normal distribution with zero mean and unit variance, referred
to as the standard normal deviate (z score), and are given by
), and a
percentile of the normal distribution with zero mean and unit variance, referred
to as the standard normal deviate (z score), and are given by
The NHANES 1999-2002 sample is a multistage, area, probability sample. The number of independent pieces of information, or degrees of freedom, depends upon the number of PSUs rather than on the number of sample persons. (See "Key Concepts about Degrees of Freedom for Performing Statistical Tests and Calculating Confidence Limits" in the Variance Estimation module for a more detailed discussion about correctly determining the number of the degrees of freedom.) Sample persons within a given PSU are not independent. (See module on Sample Design for more information.) Therefore, the standard normal deviate is replaced by a t-statistic with degrees of freedom equal to the difference between the number of PSUs and the number of strata containing observations. The endpoints for a confidence interval for the NHANES 1999-2002 survey are given by
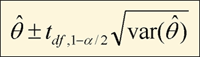 (2)
(2)
Sample weights must be incorporated in calculating the estimate and its standard error (see the Weighting module for more information) and design-based methods must be used to estimate the standard error (see the Variance Estimation module for more information). Taylor Series Linearization is one example of a design-based method. The design variables needed to obtain estimates of standard errors through this method are provided on the demographic files for the continuous NHANES (see below for an example of a program).
Confidence intervals, as constructed above, are based on one possible sample from a finite population. Many possible samples of the same size can be obtained using the same procedures and measurements. For each of these samples, a confidence interval can be constructed. For a 95% CI, 95% percent of these intervals would then contain θ .
Some variables in NHANES are highly skewed. In this case, transformations are recommended. One of the most common transformations used in the literature is the loge. We recommend that users verify that the transformed variable is normally distributed before proceeding to construct a confidence interval. This can be done using SAS proc univariate with the plot and the normal options included. The output from this procedure includes a plot of the distribution of the transformed variable and a Q-Q plot, i.e. a plot of the un-weighted variable against the standard normal variable. If the plot of a straight line through the origin and at a 45o angle is obtained, the variable is normally distributed. Also included in the output are estimates of the third (skewness) and fourth (kurtosis) moments about the mean. Once users verify that the log transformed variable is approximately normally distributed, they can estimate the geometric mean and standard error and can then construct a 95% CI.
In order to do this, you can construct the 95 percent confidence interval of your estimate on the log scale using the standard t-statistic and then back transform the upper and lower limits. However, the geometric mean and its standard error can be obtained directly from SUDAAN proc descript and then outputted to a SAS dataset where the confidence interval can be constructed directly.
At the present time, SAS proc surveymeans does not have an option to produce geometric means and their standard errors. However, they can be obtained by running proc surveymeans on the log transformed variables to produce means and standard errors of the log transformed variable, constructing the confidence interval on the log-transformed scale, and then back transforming the endpoints.
Applying the log-transformation does not necessarily yield a normally distributed random variable. Furthermore, in instances in which 0 is a plausible value, the log is undefined. We recommend that users try other transformations, for example the square root, in these instances. (Reference Visualizing Data by William Cleveland.)