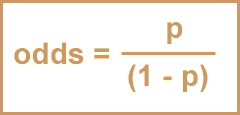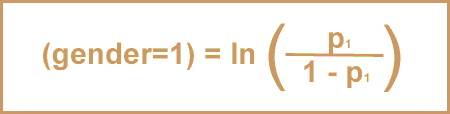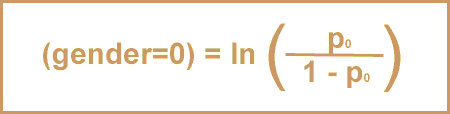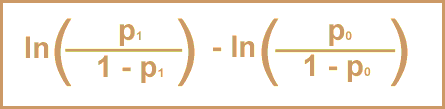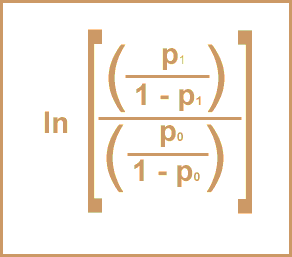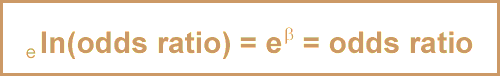Logistic Regression is used to assess the likelihood of a disease or health condition as a function of a risk factor (and covariates). Both simple and multiple logistic regression, assess the association between independent variable(s) (Xi) -- sometimes called exposure or predictor variables — and a dichotomous dependent variable (Y) — sometimes called the outcome or response variable. Logistic regression analysis tells you how much an increment in a given exposure variable affects the odds of the outcome.
Simple logistic regression is used to explore associations between one (dichotomous) outcome and one (continuous, ordinal, or categorical) exposure variable. Simple logistic regression lets you answer questions like, "how does gender affect the probability of having hypertension?
Multiple logistic regression is used to explore associations between one (dichotomous) outcome variable and two or more exposure variables (which may be continuous, ordinal or categorical). The purpose of multiple logistic regression is to let you isolate the relationship between the exposure variable and the outcome variable from the effects of one or more other variables (called covariates or confounders). Multiple logistic regression lets you answer the question, "how does gender affect the probability of having hypertension, after accounting for — or unconfounded by — or independent of – age, income, etc.?" This process — accounting for covariates or confounders — is also called adjustment.
Comparing the results of simple and multiple logistic regression can help to answer the question "how much did the covariates in the model alter the relationship between exposure and outcome (i.e., how much confounding was there)?"
In this module, you will assess the association between gender (the exposure variable) and the likelihood of having hypertension (the outcome). You will look at both simple logistic regression and then multiple logistic regression. The multiple logistic regression will include the covariates of age, cholesterol, body mass index (BMI) and fasting triglycerides. This analysis will answer the question, what is the effect of gender on the likelihood of having hypertension – after controlling for age, cholesterol, BMI, and fasting triglycerides?
As noted, the dependent variable Yi for a Logistic Regression is dichotomous, which means that it can take on one of two possible values. NHANES includes many questions where people must answer either “yes” or “no”, questions like “has the doctor ever told you that you have congestive heart failure?”. Or, you can create dichotomous variables by setting a threshold (e.g., “diabetes” = fasting blood sugar > 126); or by combining information from several variables. In this module, you will create a dichotomous variable called “hyper” based on two variables: measured blood pressure and use of blood pressure medications. In SUDAAN, SAS Survey, and Stata, the dependent variable is coded as 1 (for having the outcome) and 0 (for not having the outcome). In this example, for people who have been told they have hypertension or reported use of blood pressure medication, the hypertension variable would have a value of 1, while people who were never told of hypertension or not taking blood pressure medication would have a value of 0.
The independent variables Xj can be dichotomous (e.g. gender ,"high cholesterol"), ordinal (e.g. age groups, BMI categories), or continuous (e.g. fasting triglycerides).
Since you are trying to find associations between risk factors and a condition, you need a formula that will allow you to link these variables. The logit function that you use in logistic regression is also known as the link function because it connects, or links, the values of the independent variables to the probability of occurrence of the event defined by the dependent variable.
|
|
In the logit formula above, E(Yi)=pi implies that the Expected Value of (Yi) equals the probability that Yi=1. In this case, ‘Log' indicates natural Log.
Click here to read the optional material.
The statistics of primary interest in logistic regression are the b coefficients ( b1,b2,b3... ), their standard errors, and their p-values. Like other statistics, the standard errors are used to calculate confidence intervals around the beta coefficients.
The interpretation of the beta coefficients for different types of independent variables is as follows:
If Xj is a dichotomous variable with values of 1 or 0, then the b coefficient represents the log odds that an individual will have the event for a person with X j=1 versus a person with Xj=0. In a multivariate model, this b coefficient is the independent effect of variable X j on Yi after adjusting for all other covariates in the model.
If Xj is a continuous variable, then the eb represents the odds that an individual will have the event for a person with Xj=m+1 versus an individual with Xj=m. In other words, for every one unit increase in Xj, the odds of having the event Yi changes by eb , adjusting for all other covariates in a multivariate model.
A summary table about interpretation of beta coefficients is provided below:
| Independent Variable Type | Example Variables | The b coefficient in simple logistic regression | The b coefficient in multiple logistic regression |
|---|---|---|---|
| Continuous | height, weight, LDL |
The change in the log odds of the dependent variable per 1unit change in the independent variable. |
The change in the log odds of dependent variable per 1 unit change in the independent variable after controlling for the confounding effects of the covariates in the model. |
| Categorical (also known as discrete) | sex (two subgroups - men and women. This example will use men as the reference group.) |
The difference in the log odds of the dependent variable for one value of categorical variable vs. the reference group (for example, between women, and the reference group, men). |
The difference in the log odds of the dependent variable for one value of categorical variable vs. the reference group (for example, between women and the reference group, men), after controlling for the confounding effects of the covariates in the model. |
It is easy to transform the b coefficients into a more interpretable format, the odds ratio, as follows:
eb = odds ratio
Odds and odds ratios are not the same as risk and relative risks.
Odds and probability are two different ways to express the likelihood of an outcome.
Here are their definitions and some examples.
Definition |
Example: Getting heads in a 1 flip of a coins |
Example: Getting a 1 in a single roll of a dice |
|
|---|---|---|---|
Odds |
# of times something |
= 1/1 = 1 (or 1:1) | = 1/5 = 0.2 (or 1:5) |
Probability |
# of times something |
= 1/2 = .5 (or 50%) | = 1/6 = .16 (or 16%) |
Few people think in terms of odds. Many people equate odds with probability and thus equate odds ratios with risk ratios. When the outcome of interest is uncommon (i.e. it occurs less than 10% of the time), such confusion makes little difference, since odds ratios and risk ratios are approximately equal. When the outcome is more common, however, the odds ratio increasingly overstates the risk ratio. So, to avoid confusion, when event rates are high, odds ratios should be converted to risk ratios. (Schwartz LM, Woloshin S, Welch HG. Misunderstandings about the effects of race and sex on physicians’ referrals for cardiac catheterization. N Engl J Med 1999;341:279–83) There are simple methods of conversion for both crude and adjusted data. (Zhang J, Yu KF. What's the relative risk? A method of correcting the odds ratio in cohort studies of common outcomes. JAMA 1998;280:1690-1691. Davies HT, Crombie IK, Tavakoli M. When can odds ratios mislead? BMJ 1998;316:989-991)
The following formulas demonstrate how you can go between probability and odds.
 |
References:
Logistic Regression Using the SAS System
By Paul D. Allison
Epidemiology
By Leon Gordis