NHANES III data are NOT obtained using a simple random sample. Rather, a complex, multistage, probability sampling design is used to select participants representative of the civilian, non-institutionalized US population. The sample does not include persons residing in nursing homes, members of the armed forces, institutionalized persons, or U.S. nationals living abroad.
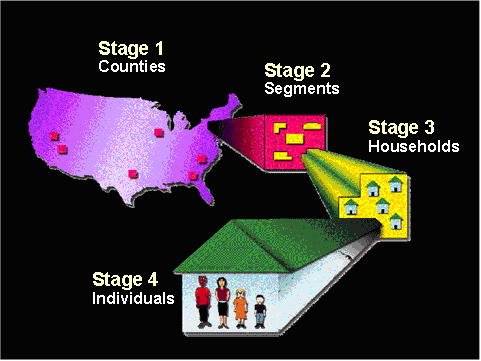
The NHANES III sampling procedure consists of 4 stages, shown and described below.
A sample weight is assigned to each sample person. It is a measure of the number of people in the population represented by that sample person in NHANES III, reflecting the unequal probability of selection, nonresponse adjustment, and adjustment to independent population controls. When unequal selection probability is applied, as in the NHANES III sample, the sample weights are used to produce an unbiased national estimate. More information about sample weights and how they are created can be found in the Weighting module.
NHANES III was designed to sample larger numbers of certain subgroups of particular public health interest. Oversampling was done to increase the reliability and precision of estimates of health status indicators for these population subgroups.
Different subgroups have been oversampled in other survey years. For example, during the late 1960s and early 1970s, there was concern that people of very low income and women of childbearing age were at greater risk of malnutrition than the general population. Therefore, during the first National Health and Nutrition Examination Survey (NHANES I), conducted in 1971-74, these subgroups were oversampled. In future surveys, different subgroups may be oversampled depending on public health trends.
NHANES III sampling frame covered samples persons age 2 months and older. In NHANES III, young children, older persons (age 65+ years), black persons, and Mexican Americans were the subgroups that were oversampled.
For your own analyses, it is critical to carefully review the documentation for each survey cycle to determine which subgroups were oversampled.
The NHANES III sample represented the total civilian, non-institutionalized population, two months of age or over, in the 50 states and the District of Columbia of the United States. The first stage of the design consisted of selecting a sample of 81 PSUs that were mostly individual counties. In a few cases, adjacent counties were combined to keep PSUs above a minimum population size. The PSUs were stratified and selected with probability proportional to size (PPS). Thirteen large counties (strata) were chosen with certainty (probability of one). For operational reasons, these 13 certainty PSUs were divided into 21 survey locations. After the 13 certainty strata were designated, the remaining PSUs in the United States were grouped into 34 strata, and two PSUs were selected per stratum (68 survey locations). The selection was done with PPS and without replacement. The NHANES III sample therefore consists of 81 PSUs or 89 locations.
NHANES III was conducted over a 6 year period (1988-1994). In the NHANES III sample, 89 survey locations were randomly divided into 2 sets or phases, the first consisting of 44 and the other, 45 locations. One set of primary sampling units (PSUs) was allocated to the first 3-year survey period (1988-91) and the other set to the second 3-year period (1991-94). Therefore, unbiased national estimates of health and nutrition characteristics can be independently produced for each phase as well as for both phases combined.
Computation of national estimates from both phases combined (i.e. total NHANES III) is the preferred option; individual phase estimates may be highly variable. In addition, individual phase estimates are not statistically independent. It is also difficult to evaluate whether differences in individual phase estimates are real or due to methodological differences. That is, differences may be due to changes in sampling methods or data collection methodology over time. At this time, there is no valid statistical test for examining differences between phase 1 and phase 2.
As with NHANES 1999-2004, the PSUs in NHANES III are selected from strata defined by geography and proportions of minority populations. Each stratum contains two PSUs. Together, these strata and the PSUs represent the variance units (sampling units used to estimate the sampling error).
Unlike in continuous NHANES where masked variance units (MVUs) were used, NHANES III did not create MVUs, Instead, PSEUDO primary sampling units and stratification variables are provided. In NHANES III, 49 pseudo strata and 98 pseudo-PSUs were created for variance estimation. The stratum variable name for NHANES III is SDPSTRA6, and the PSU variable name is SDPPSU6.