8. Nutrición y Medidas Antropométricas
En varios países las “medidas antropométricas” han sido un componente importante de las encuestas en salud reproductiva. En el pasado, la población de referencia que se utilizó se basó en la acumulación de datos de diferentes fuentes de la población norteamericana a lo largo de las décadas del 60 y 70. Además de datos de varias encuestas, la población de referencia incorporaba datos de los registros civiles. Por supuesto era una población de referencia empírica sin mayores controles. En mayo 2000 CDC actualizó la población de referencia utilizando 5 encuestas nacionales. A finales de la década del 90 la OMS comenzó un estudio en 6 países del mundo (Brasil, los Estados Unidos de América, Ghana, la India, Noruega y Omán) con el objetivo de desarrollar una población de referencia nueva que describiría la forma que las niñas y los niños deberían crecer. Por el contrario, este estudio usó una única metodología e incorporó controles asociados con una lactancia materna apropiada y condiciones ambientales. Así excluyó situaciones o condiciones que fueran dañinas para el crecimiento apropiado de las niñas y los niños, como ambientes contaminados e insalubres o si la madre fumaba. En 2006 la OMS introdujo el nueva patrón o referente basado en este trabajo para evaluar la situación de crecimiento y desarrollo de los niños y las niñas.
El algoritmo para convertir estas medidas de peso y talla en “puntos-Zs” se encuentra en el sitio web de OMS: http://www.who.int/childgrowth/software/es/index.html (en español) y existe para los paquetes estadísticos SAS, SPSS, Stata y S-Plus. Al momento de elaborar este documento OMS proporcionaba la versión 3.2.2 de enero de 2011, que agrega el cálculo de intervalos de confianza además de los “puntos-Zs”. Debe notar que los paquetes estadísticos trabajan de formas diferentes. Lo que sigue es una descripción sencilla para trabajar fácilmente con el algoritmo de SPSS provisto por OMS y los datos de la encuesta. Más recursos y manuales existen en el sitio web para mayor información y/o explicaciones.
Procedimiento:
1. Crear en C:\ un directorio
C:\OMS
2. Dentro de este directorio crear un sub-directorio: igrowup_SPSS_new
Su estructura entonces sería: C:\OMS\igrowup_SPSS_new\
Estos nombres de directorios o carpetas son una sugerencia, el usuario puede crear su propia estructura y su propia nomenclatura.
NOTA: Por razones de organización de archivos, el ToolKit usa la siguiente estructura:
c:\TOOLKit_SPS\4.Analisis y Sintaxis\NUT_OMS\
3. Para bajar los algoritmos que provee la OMS, vaya al siguiente enlace:
http://www.who.int/childgrowth/es/
En el menú de la izquierda, haga click en Software y baje el cursor hasta encontrar las Macros:
4. Bajar (Download) y expandir o descomprimir el archivo *.zip de la macro para SPSS (llamada ‘igrowup_SPSS_new.zip), dentro de la carpeta:
C:\OMS\igrowup_SPSS_new\
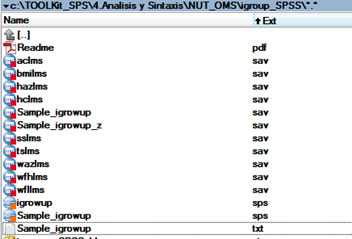
5. Notar que esta nueva carpeta contiene 9 bases de dados (.SAV) que el programa va utilizar para crear los punto-Zs; dos bases de datos ejemplares (.SAV), y dos programas SPSS (.SPS) para procesar los dados ejemplares. El programa “igroup.sps” contiene el macro-algoritmo que el usuario tiene que modificar – para procesar sus propias bases de datos (de la encuesta).
Nota: el programa igroup.sps corresponde a 8.2.RHS_igrowup.sps en el toolkit.
6. En SPSS, usando el archivo “Hijos” de la encuesta (“RHS_hijos” en el Toolkit), crear una base de datos para uso con el programa “igroup.sps” (“8.2.RHS_igrowup.sps” en el Toolkit) con solamente las variables esenciales, y excluyendo niños mayores de 5 años (sin casos con imputación de mes o año), y que no viven en el hogar:
- Identificador del segmento (‘PSU’ o “Segmento”)
- Identificador del hogar (‘Hogar’)
- Identificador del hijo (pe. ‘P1010’)
- Región o departamento (‘region’)
- Área (‘area’)
- Peso de ponderación (‘pesomef’)
- Variables que identifica día, mes y año de nacimiento del hijo (dnac, mnac, anac)
- Variables que identifica día, mes y año de medición.
- Talla
- Peso
Nota: El usuario debe Guardar esta base de datos en el mismo directorio en donde están las 9 bases de datos que el programa va utilizar. (C:\OMS\Igrowup_SPSS_new\) = a (c:\TOOLKit_SPS\4.Analisis y Sintaxis\NUT_OMS\ en el toolkit.
.
ADEMAS: el usuario debe crear una variable que se llama ‘casenum’ combinando los identificadores de segmento, hogar y niño/hijo para posteriormente ligar/asociar las variables nuevas creadas (puntos-Zs y banderas o flags para casos fuera de rango).
7. Vea la sintaxis en el archivo: 8.1.RHS_Cap_Nutricion [ZIP-3K]
Este incluye los comandos utilizados para preparar los datos de una encuesta RHS.
8. En el programa “igrowup_SPSS.sps” se crean (o renombran) las variables utilizadas por el programa igrowup_SPSS.sps, que son:
- sex (sexo del niño 1= varon, 2=mujer)
- agedays3 (y/o) agemos (edad en días y/o en meses)
- weight2 (peso)
- length (talla)
- lorh (posición: 1=acostado, 2=parado)
- wgting (peso de ponderación)
- y las variables “hc”, “ac”, “ts”, “ss” y “oedema” se refieren a otras medidas antropométricas que raramente se recoletan en las encuestas demográficas y de salud reproductiva. Estas últimas solamente necesita crear y declarar como en blanco o “missing”.
- Luego de verificar Salvar el programa ‘igrowup.sps’ con otro nombre como se ha hecho para el Toolkit. Este proceso sorresponde a 8.2.RHS_igrowup.sps.
Para referencia vea la sintaxis: 8.2.RHS_igrowup [ZIP-9K]
* SECCION para RENOMBRAR las variables esenciales (requerido en sintáxis de OMS).
COMPUTE casenum=(clave*100)+p002. /* Crea la variable "casenum" que es la clave de identificación única para cada niño.
RENAME VARIABLES (AREA=URBANR).
COMPUTE FechMed=DATE.DMY(p011d, p011m, entano).
COMPUTE FechNac=DATE.DMY(p005d, P005m, P005y).
COMPUTE agedays3=DATEDIFF(FechMed, FechNac, "days").
COMPUTE agemos=(agedays3/30.4375).
compute wgting=pesomef.
compute weight2=p010.
missing values weight2 (88.80).
compute sex=c020.
compute length=p008.
missing values length (888.80).
compute lorh=p009.
missing values lorh (9).
STRING oedema (A1).
compute oedema="n".
compute hc=9.
compute ac=9.
compute ts=9.
compute ss=9.
MISSING VALUES hc ac ts ss (9). /* Declara missing en las variables hc ac ts ss, que se refieren a otras medidas antropométricas que no se han recolectado en las ESR.
compute agedays2=rnd(agedays3).
9. Procese los datos de la encuesta utilizando sus nuevas sintaxis, que para el Toolkit son:
8.1.RHS_Cap_Nutricion.SPS (Lea las líneas de comentarios al inicio de la sintaxis y siga las instrucciones sobre cómo debe correr)
8.2.RHS_igrowup.sps
10. Evaluar los resultados y hacer una liga de las variables claves creadas: (Este parte del proceso corresponde al * Proceso C. dentro de la sintáxis 8.1.RHS_Cap_Nutricion.SPS )
- Variables whzflag, hazflag y wazflag son banderas (0,1) que indican si los valores originales estuvieron fuera del posible (para Peso/Talla, Talla/Edad y Peso/Edad), 0 si están dentro del rango esperado y 1 sino.
- Guardar la variable ‘casenum’ de identificación más las variables creadas utilizando la base de datos que el programa creó: filename_z.sav.
- agemos,
- zhaz (puntaje-Z para Talla/Edad)
- zwaz (puntaje-Z para Peso/Edad)
- zwhz (puntaje-Z para Peso/Talla)
- hazflag
- wazflag
- whzflag
- Hacer la combinación (MATCH CASES) con su base de datos “hijos” agregando las nuevas variables creadas por el programa ‘igrowup.SPS’ modificado de OMS.
- Basado en las variables hazflag, wazflag, y whzflag puede crear una variable-bandera para excluir casos que están fuera de rangos posibles.
- Y en función de zhaz, zwaz y zwhz crear sus variables dummy de malnutrición:
- TEm2 o HAZm2 (< -2 SD para T/E; var 0/1 para Retardo en crecimiento)
- TEm3 o HAZm3 (<-3 SD para T/E; var 0/1 para Retardo extremo en crecimiento)
- PEm2 o WAZm2 (<-2 SD para P/E; var 0/1 para Peso bajo)
- PEm3 o WAZm3 (<-3 SD para P/E; var 0/1 para Extremo peso bajo)
- PTm2 o WHZm2( < -2 SD para P/T; var 0/1 para Emaciacion)
- PTm3 o WHZm3( < -3 SD para P/T; var 0/1 para Emaciacion severa)
- PTp2 o WHZp2 (P/T >= 2 SD; var 0/1 para Sobrepeso)
Ir a Estimación de los errores de muestreo de las ESR
![]() Los enlaces a organizaciones no federales se ofrecen solamente como un servicio a nuestros usuarios. Estos enlaces no constituyen un respaldo de los CDC ni del gobierno federal a estas organizaciones o a sus programas, ni debe inferirse respaldo alguno. Los CDC no se hacen responsables por el contenido de las páginas web de organizaciones individuales que pueda encontrar en estos enlaces.
Los enlaces a organizaciones no federales se ofrecen solamente como un servicio a nuestros usuarios. Estos enlaces no constituyen un respaldo de los CDC ni del gobierno federal a estas organizaciones o a sus programas, ni debe inferirse respaldo alguno. Los CDC no se hacen responsables por el contenido de las páginas web de organizaciones individuales que pueda encontrar en estos enlaces.
Reciba actualizaciones por correo electrónico
Para recibir actualizaciones de esta página, ingrese su correo electrónico:
Contáctenos:
- Centros para el Control y la Prevención de Enfermedades
1600 Clifton Rd
Atlanta, GA 30333 - 800-CDC-INFO
(800-232-4636)
TTY: (888) 232-6348
24 Horas/Todos los días - cdcinfo@cdc.gov
